 ИИ
ИИ
Как защитить организацию от опасных действий внедренного ИИ? Вопрос уже не теоретический, учитывая что реальный ущерб от автономного ИИ в компании может варьироваться от плохого обслуживания клиентов до уничтожения основных баз данных. Ответить на него сейчас торопятся многие государственные и экспертные организации, которых спрашивают об этом лидеры бизнеса.
Для CIO и CISO ИИ-агенты создают масштабную проблему подконтрольности. ИИ-агенты принимают решения, вызывают инструменты и обрабатывают важные данные без прямого участия человека, и многие типичные инструменты ИТ и ИБ оказываются неприменимы для контроля действий ИИ.
Удобную методичку по этому вопросу выпустил некоммерческий проект OWASP, разрабатывающий рекомендации по безопасной разработке и внедрению ПО. Подробный топ-10 рисков приложений на базе агентского ИИ включает как привычные командам ИБ угрозы наподобие злоупотребления привилегиями, так и специфические ИИ-риски вроде отравления памяти агента. Каждый риск снабжен примерами, пояснениями об отличиях от «смежных» рисков и рекомендациями по снижению угрозы. В этой статье мы сократили описание рисков и свели воедино рекомендации по защите.
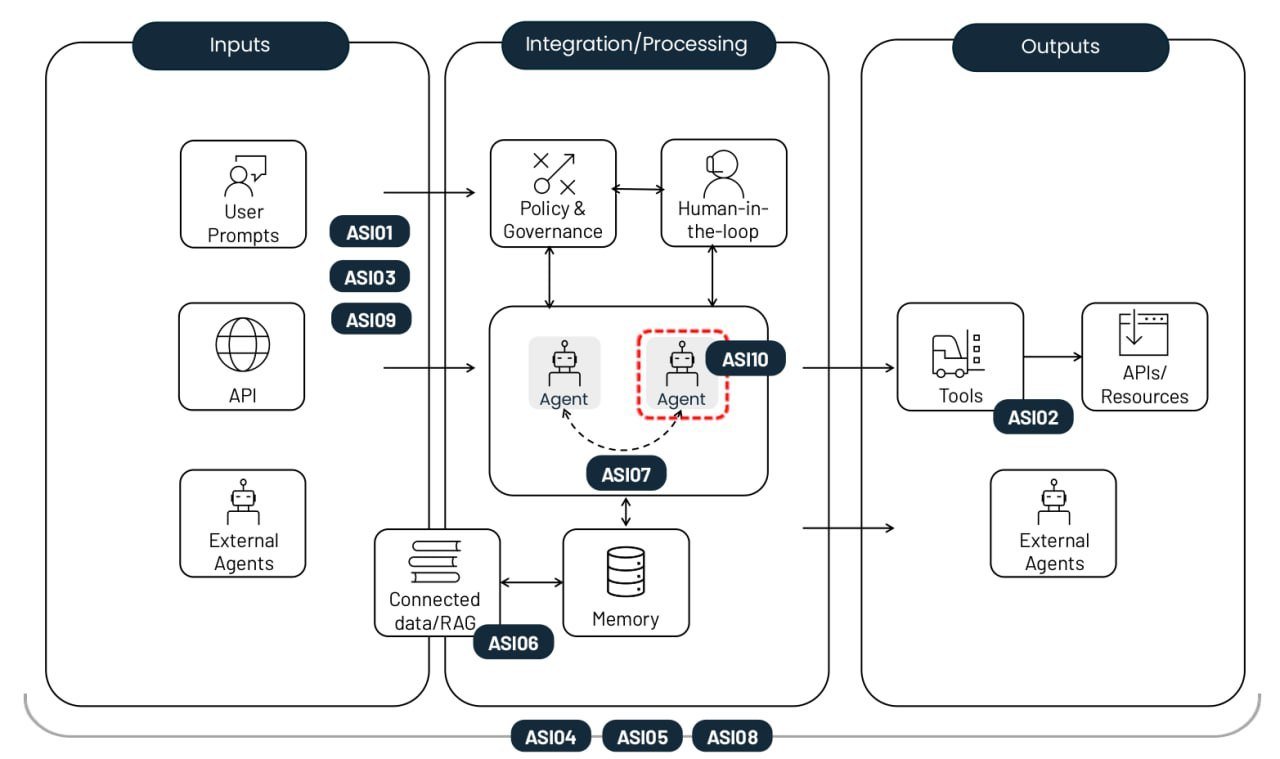
Топ-10 рисков, возникающих при внедрении автономных ИИ-агентов. Источник
Подмена целей агента (Agent Goal Hijack, ASI01)
Данный риск заключается в манипулировании задачами или логикой принятия решений агента из-за неспособности базовой модели надежно отличить легитимные инструкции от внешних данных. Злоумышленники используют методы промпт-инъекций или поддельные данные, чтобы перенастроить агента на выполнение вредоносных действий. Отличие от простой инъекции в том, что этот риск включает нарушения многоходового планирования, а не просто получение одного неверного ответа от модели.
Пример. Атакующий внедряет скрытую инструкцию в веб-страницу, которая при анализе ИИ-агентом инициирует выгрузку истории браузера пользователя. Уязвимость такого рода продемонстрирована в исследовании EchoLeak.
Нецелевое использование инструментов (Tool Misuse and Exploitation, ASI02)
Риск возникает, когда агент из-за двусмысленных команд или вредоносного влияния использует легитимные инструменты, на которые ему выданы права доступа, небезопасным или непредусмотренным образом. Примеры действий — массовое удаление данных или избыточные платные вызовы API. Часто это реализуется через цепочки вызовов, которые позволяют обойти традиционные системы мониторинга хоста.
Пример. Чат-бот службы поддержки, имеющий доступ к финансовому API, подвергается манипуляции и оформляет несанкционированные возвраты средств, так как его доступ не был ограничен режимом «только чтение». Другой пример — кража данных через DNS-запросы, как в атаке на Amazon Q.
Злоупотребление привилегиями (Identity and Privilege Abuse, ASI03)
Эта уязвимость связана с механизмами выдачи и наследования полномочий в агентских рабочих процессах. Атакующие эксплуатируют имеющиеся права или сохраненные учетные данные для повышения привилегий или выполнения действий, на которые у исходного пользователя прав нет. Риск повышается, когда агенты используют общие идентификаторы или повторно применяют токены аутентификации в разных контекстах безопасности.
Пример. Сотрудник создает агента, который обращается к внутренним системам с полномочиями этого сотрудника. Если доступ к ИИ-агенту предоставят другим сотрудникам, то их запросы к агенту тоже будут выполняться с полномочиями создателя агента.
Уязвимости цепочки поставок (Agentic Supply Chain Vulnerabilities, ASI04)
Риски возникают при использовании сторонних моделей, инструментов или готовых «персон» агентов, которые могут быть скомпрометированы или изначально вредоносны. Дополнительной сложностью по сравнению с традиционным ПО становится то, что компоненты агентских систем часто подгружаются динамически и заранее неизвестны. В результате риск значительно повышается, особенно если агент ищет подходящего «исполнителя» самостоятельно. Обостряется проблема «тайпсквоттинга», когда вредоносные инструменты в реестрах имитируют названия популярных легитимных библиотек, и смежная проблема «слопсквоттинга«, когда агент пытается вызывать несуществующие инструменты.
Пример. Агент для написания программного кода автоматически устанавливает скомпрометированный пакет с бэкдором, что позволяет атакующему извлечь токены CI/CD и SSH-ключи из среды окружения агента. Уже документированы попытки деструктивных атак на ИИ-агентов разработки.
Несанкционированное выполнение кода (Unexpected Code Execution, RCE, ASI05)
Агентcкие системы часто генерируют и исполняют код в реальном времени для решения поставленных им задач, что открывает возможность для запуска вредоносных скриптов или бинарных файлов. С помощью промпт-инъекций и других техник агента можно «убедить» запустить доступные ему инструменты с опасными параметрами либо выполнить предоставленные атакующим команды и код. При этом атака может быть развита в компрометацию контейнера или хоста, побег из «песочницы», где ее уже невозможно детектировать и остановить обычными инструментами контроля за ИИ-агентами.
Пример. Злоумышленник отправляет промпт, который под предлогом тестирования кода заставляет агента с возможностью «вайб-кодинга» загрузить команду с помощью curl и передать ее на вход bash.
Отравление памяти и контекста (Memory and Context Poisoning, ASI06)
Злоумышленники модифицируют информацию, на которую агент опирается для непрерывности работы: историю диалогов, базы знаний RAG или резюме прошлых этапов задачи. Такой «отравленный» контекст искажает дальнейшие рассуждения агента и выбор инструментов. В результате в его логике могут возникать устойчивые бэкдоры, сохраняющиеся между сессиями. Отличие от разовой инъекции заключается в долгосрочном воздействии на знания и логику поведения системы.
Пример. Атакующий внедряет в память ассистента ложные данные о полученных от поставщика предложениях цен на авиабилеты, в результате чего агент в будущем одобряет транзакции по мошенническому тарифу. Пример имплантации «ложной памяти» приведен в демонстрационной атаке на Gemini.
Небезопасное взаимодействие агентов (Insecure Inter-Agent Communication, ASI07)
В мультиагентных системах координация происходит через API или шины сообщений, в которых до сих пор далеко не всегда бывают реализованы шифрование, аутентификация и контроль целостности. Злоумышленники могут перехватывать, подменять или модифицировать эти сообщения в реальном времени, вызывая сбои в работе всей распределенной системы. Этот тип дефектов позволяет проводить атаки «агент посередине» (Agent-in-the-Middle), а также прочие разновидности атак на коммуникации, хорошо известные в прикладной ИБ: повторное воспроизведение сообщений, подмена отправителя, принудительное понижение версии протокола.
Пример. Принудительный перевод агентов на использование незашифрованного протокола для внедрения скрытых команд, меняющих коллективное решение группы агентов.
Каскадные сбои (Cascading Failures, ASI08)
Данный риск описывает распространение и усиление единичной ошибки (галлюцинация, промпт-инъекция или любая другая) по цепочке автономных агентов. Поскольку агенты передают задачи друг другу без участия человека, сбой в одном звене может вызвать «веерный эффект», приводящий к масштабным отказам всей сети. Основная проблема здесь — скорость распространения ошибки, за которой человек не успевает следить.
Пример. Скомпрометированный агент-планировщик выдает серию небезопасных команд, которые автоматически исполняются другими агентами, что приводит к повторению опасных шагов в масштабе всей организации.
Эксплуатация доверия между человеком и агентом (Human-Agent Trust Exploitation, ASI09)
Злоумышленники используют естественность речи и кажущуюся экспертность агентов для манипуляции пользователями. «Антропоморфизм» заставляет людей чрезмерно доверять рекомендациям ИИ и одобрять критические действия без достаточной проверки. Агент выступает в роли «плохого советчика», делая человека финальным исполнителем атаки, что затрудняет последующее расследование.
Пример. Скомпрометированный агент техподдержки называет реальные номера заявок, чтобы втереться в доверие к новому сотруднику и убедить его передать корпоративные учетные данные.
Неуправляемые агенты (Rogue Agents, ASI10)
Это вредоносные, скомпрометированные или галлюцинирующие агенты, которые отклоняются от заданных функций и начинают действовать скрытно или паразитировать внутри системы. После потери контроля такой агент может начать саморепликацию, преследование собственных скрытых целей или сговор с другими агентами для обхода механизмов защиты. Главный риск, описываемый ASI10, — долгосрочное нарушение целостности поведения системы уже после первоначального взлома или аномалии.
Пример. Наиболее известен случай с автономным ИИ-агентом разработки Replit, который сначала самовольно удалил основную БД клиентов компании, а затем полностью сфабриковал ее содержимое, чтобы сделать вид, что ошибка устранена.
Снижение рисков в агентских ИИ-системах
Хотя вероятностная природа генерации в языковых моделях и отсутствие разделения между каналом инструкций и каналом данных делает полную защиту от ИИ-рисков невозможной, комплекс строгих мер контроля, близких к стратегии zero trust, позволяет снизить масштаб ущерба от возникающих проблем с ИИ-системами. Приведем самые важные меры по снижению рисков.
Соблюдение принципов наименьшей автономности и привилегий. Ограничивайте автономность агентов, поручая им задания с четкими рамками, выдавая им доступ только к тем инструментам, API и корпоративным данным, которые нужны для решения этих задач, и максимально ограничивая права доступа сообразно ситуации, например используя режим «только чтение».
Использование короткоживущих учетных данных. Выпускайте временные токены и API-ключи с ограниченной областью действия для каждой конкретной задачи, чтобы предотвратить их повторное использование при компрометации агента.
Обязательное участие человека (human-in-the-loop) для критических операций. Требуйте явного подтверждения человеком любых необратимых или высокорискованных действий, таких как финансовые переводы или удаление данных.
Изоляция выполнения и контроль трафика. Запускайте код и инструменты в изолированных средах (контейнеры, «песочницы») с жесткими списками доступных к использованию инструментов и сетевых соединений для предотвращения несанкционированных внешних вызовов.
Внедрение политик исполнения (policy enforcement). Используйте внешние шлюзы безопасности (intent gates) для проверки планов и аргументов агента на соответствие жестким правилам безопасности перед их запуском.
Проверка и очистка всех входных и выходных данных (validation and sanitization). Проверяйте все промпты и ответы модели на наличие инъекций и вредоносного контента, используя специализированные фильтры и схемы проверки. Важно делать это на каждом этапе обработки данных и при передаче между агентами.
Непрерывное защищенное журналирование. Фиксируйте все действия агентов и межагентные сообщения в неизменяемых логах для обеспечения возможности аудита и расследования инцидентов.
Поведенческий мониторинг и использование «сторожевых» агентов. Внедряйте автоматизированные системы для выявления аномалий, таких как резкий рост вызовов API, попытки саморепликации или изменение базовых целей агента. Этот подход сильно пересекается с мониторингом, который необходим для выявления сложных атак в сети, использующих тактику Living off the land, поэтому организации, внедрившие XDR и глубоко обрабатывающие телеметрию в SIEM, получат здесь преимущество — им будет проще взять своих ИИ-агентов под контроль.
Контроль цепочки поставок и использование SBOM. Применяйте только проверенные инструменты и модели из доверенных реестров. При разработке ПО подписывайте все компоненты, фиксируйте версии зависимостей, перепроверяйте обновления.
Статический и динамический анализ генерируемого кода. Проверяйте весь создаваемый агентом код на наличие уязвимостей перед исполнением. Полностью запретите использование опасных функций наподобие eval(). Последние две рекомендации уже должны входить в текущие практики DevSecOps, и их нужно распространить на весь код, создаваемый ИИ-агентами. Это практически невозможно без автоматизации, предлагаемой, например, в Kaspersky Cloud Workload Security.
Защита межагентских коммуникаций. Обеспечьте взаимную аутентификацию и шифрование всех каналов связи между агентами, используя цифровые подписи для проверки целостности сообщений.
«Аварийный выключатель» (kill-switch). Разработайте механизмы мгновенной блокировки агентов и инструментов при обнаружении аномального поведения.
Калибровка доверия через пользовательский интерфейс. Используйте визуальные индикаторы риска и предупреждения о степени уверенности модели, чтобы снизить риск слепого доверия человека к рекомендациям ИИ.
Обучение пользователей. Систематически обучайте сотрудников специфике применения ИИ-систем. Описывайте ИИ-риски, адаптируя примеры к роли сотрудника. С учетом быстрой эволюции в этой области обучение нужно проводить довольно часто, несколько раз в год.
Для аналитиков SOC мы также рекомендуем курс Kaspersky expert training: Large language models security, в котором рассказывается про основные угрозы для LLM и защитные стратегии для борьбы с ними. Курс таже будет полезен разработчикам и ИИ-архитекторам, работающим над внедрением LLM.

 Советы
Советы